1. inleiding
We kennen natuurlijke talen zoals het Nederlands maar we kennen ook programmeertalen zoals Java. Een formele taal heeft een veel eenvoudigere structuur dan een natuurlijke taal en is daarom makkelijker te automatiseren.
We bestuderen in deze cursus de theorie van formele talen en de daarbij behorende automaten en grammatica. Het bestuderen is een onderdeel van Computational Thinking en helpt je om je eigen denkniveau naar een hoger level te krijgen. Een strategie die vaak wordt toegepast is het opsplitsen van een groter probleem in kleinere stukjes.
De automaten die wij gaan bestuderen zijn voorlopers van de Turing machine ontwikkeld door de wiskundige Alan M. Turing. De Turing machine is een mechanisme dat symbolen manipuleert en men kan hiermee de logica van elke mogelijke computer simuleren. Het is al in 1936 bedacht.
Een formele taal kan op drie manieren worden weergegeven:
- In de vorm van een grammatica. Een grammatica zijn de regels van de taal zoals bijvoorbeeld de lengte van een zin of hoe de zin moet worden samengesteld.
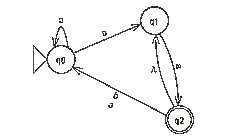
- In de vorm van een automaat. Een automaat is een graaf die bedoeld is om te checken of een bepaalde zin of woord wordt geaccepteerd.
- In de vorm van een reguliere expressie. Een reguliere expressie geeft een beschrijving van een taal. De expressie a* geeft aan dat er 0 of meer a's in de zin zitten.
2. Wat is een taal?
Het woord taal kan verschillende betekenissen hebben. In het algemeen zou je kunnen zeggen dat taal een systeem is om ideeën, feiten of concepten uit te drukken. Iedere taal heeft een verzameling symbolen zoals het alfabet. Ook heeft een taal regels om met die symbolen te werken zoals de Nederlandse grammatica.
Er zijn twee soorten talen:
- Natuurlijke talen: Dit zijn talen die in de loop van de tijd zijn ontstaan zoals bijvoorbeeld het Engels.
- Formele talen: Dit zijn kunstmatige talen. Een programmeertaal is altijd een kunstmatige taal. Esperanto is ook een kunstmatige taal.
Een taal kan worden geformuleerd als een zekere hoeveelheid strings die zijn geformeerd met karakters uit een zekere verzameling. Het Nederlands is opgebouwd uit strings (woorden) die zijn gevormd uit de verzameling van het alfabet. Uit deze woorden kunnen een bijna oneindige hoeveelheid zinnen worden gevormd.
Een taal is dus vaak een verzameling karakters. Een verzameling van een taal duiden we aan met het ∑ (sigma) teken. De verzameling van de woorden van de taal Nederlands is ∑={a,b.....z, A....Z}. Dit geldt ook voor de taal Engels. De talen Nederlands en Engels hebben dus hetzelfde alfabet of dezelfde verzameling maar vormen met die verzameling karakters verschillende woorden waardoor er een verschillende taal ontstaat. Een verzameling is dus niet hetzelfde als een taal.
3. Het lambda symbool
Stel dat we uitgaan van het volgende alfabet:
∑ = {a,b}
We kunnen dan alle strings definiëren als
L = {a,b,aa,ab,ba,bb,aaa,aaab.....}. De woorden van deze taal zijn echter niet compleet. We kunnen namelijk ook een lege string produceren. Dat schrijven we met het teken λ. Dit is het zogenaamde lambda-teken (spreek uit: labda).
De complete verzameling is dus L = {λ, a,b,aa,ab,ba,bb,aaa,aaab.....}
Je ziet dus dat bij een taal ook altijd een lege string hoort (tenzij we dat anders aangeven). Er valt ons nog iets op. De bovenstaande verzameling ∑ eindigt met .... Dit geeft aan dat de taal oneindig is. We kunnen dus een oneindig aantal woorden maken. Oneindige talen zijn vaak niet interessant.
De Kleene ster
Hierboven hebben we de gehele bovenstaande taal aangegeven met ∑ = {λ,a,b,aa,ab,ba,bb,aaa,aaab.....}.. Dit kan ook anders namelijk met ∑*.De ster noemen we de Kleene closure. We kunnen bijvoorbeeld zeggen dat L1= {a,b,ab,ba} en L0= {λ}. ∑* is dan L0 ∪ L1 en is dus de verzameling {λ,a,b,ab,ba}. ∑* is de vereniging van de talen L0 en L1.
We kunnen de hele taal ook zonder lambda aangeven. Dit duiden we aan met ∑+. Dus
∑+=∑* - {λ}.
4. De inverse, de lengte en de formele schrijfwijze
De lengte van een string geven we aan met |w| waarbij het symbool w staat voor de string zit. Beschouw w als een variabele. Dus als w 2 karakters heeft dan schrijven we |w|=2. Dit mag bijvoorbeeld ook: |w| ≤ 2.
Stel dat we een taal construeren met ∑={a,b} en L={aa,bb}. Je kunt nu zeggen dat de taal L'={λ,a,b,ab,ba} waarbij geldt dat |w| ≤ 2. We noemen L' de inverse van de taal L. L ∪ L' = {λ,a,b,ab,ba,aa,bb} met |w| ≤ 2 is alles bij elkaar. Het ∪ betekent de vereniging van en is dus niets anders dan de twee verzamelingen bij elkaar voegen.
Voor L ∪ L' met |w| ≤ 2 is ook een formele schrijfwijze:
L={w∈{a,b}* : |w| ≤ 2}
Als we de restrictie |w| ≤ 2 laten vervallen dan krijg je L ∪ L' = ∑*
5. Grammatica
Om talen binnen de informatica te kunnen te bestuderen hebben we een systeem nodig om ze te kunnen beschrijven. We hebben al een formele schrijfwijze maar deze is beperkt. We hebben een complexer systeem nodig.
Als we de Nederlandse taal ontleden dan zien we het volgende:
- zin: bestaat uit:
- het gezegde bestaat uit:
- onderwerp: bestaat uit:
- lidwoord
- zelfstandig naamwoord
Nu kun je het volgende onderscheiden:
- Productieregels zijn regels om een zin te maken en vormen het hart van de grammatica. Bijvoorbeeld: elke zin heeft een onderwerp en een gezegde want anders is het geen zin. We duiden dit aan met een P
- De zin is het startsymbool of hoofdsymbool. We duiden dit aan met een S
- Daaronder vallen de hulpsymbolen: het gezegde, het onderwerp, het lidwoord, werkwoord en het zelfstandig naamwoord. We duiden dit aan met V van variable. Het is dus alles wat geen eindsymbool is.
- Als laatste zijn er de eindsymbolen. Dit zijn symbolen die niet verder te ontleden zijn zoals de, man of hond. We duiden dit aan met een T (terminals).
Nu hebben we een grammatica die we als volgt kunnen definiëren:
G={V,T,S,P}
6. Productieregels van een formele taal
Stel dat we van een formele taal zeggen dat de productieregels zijn van de vorm
x → y
Hier staat: in de plaats van een x schrijf je een y.
x is een element van V(dus alle hulpsymbolen) en y is een element van (V ∪ T), een combinatie van hulp en eindsymbolen . Dit betekent dus alle afleidingen die je kunt maken van de hulpsymbolen (V) en eindsymbolen (T). We kunnen hierbij ook nog een speciaal hulpsymbool gebruiken, namelijk het startsymbool S.
Stel nu dat we een string willen maken van de vorm ab. Dan schrijven we het volgende:
We beginnen met een hulpsymbool S (startsymbool).
S →
Deze laten we verwijzen naar een a, dus in de plaats van S schrijven we een a.
S → a
Nu moeten we nog een b produceren. Dat zouden we als volgt kunnen doen:
S → aB
B → b
Als we hier nu een afleiding van maken krijgen we de string ab.
Dus S => aB => ab
7. Een stapje verder
We gaan nu een stapje verder. We definiëren een grammatica als volgt:
G=({S},{a,b},S,P)
Dus {a,b} zijn de eindsymbolen
De productieregels P zijn
S → aSb
S → λ
Je mag dus nu kiezen. S kan zowel aSb worden of de lege string. Als je kiest voor de eerste regel komen we een fenomeen tegen wat we recursie noemen.
S⇒aSb⇒aaSbb⇒aabb.
Bij de laatste afleiding hebben we gekozen voor de tweede productieregel maar we hadden oneindig door kunnen gaan.
De productieregels kunnen we ook anders opschrijven in de vorm van een grammatica:
L(G)={anbn : n ≥ 0}
Let er nu op dat er geen komma staat tussen a en b. Deze eindsymbolen worden nu aan elkaar geschreven. Daardoor is een afleiding die leidt tot ba niet mogelijk.
8. Andersom redeneren
Ingewikkelder wordt het wanneer je van een formele beschrijving van een taal de productieregels moet geven. Neem de volgende taal:
L={anbm : n ≥ 0, m > n}
Hoe ontwikkel je hier nu productieregels van? Laten we beginnen met de taal informeel te omschrijven. Er kunnen 0 of meer a-strings worden geformeerd en er is altijd één b meer dan een a. Hieruit kun je concluderen dat er minimaal één b moet zijn.
Een regel zou dan kunnen zijn:
S → aSb | b
S → λ
Kun je zien wat hier fout aan is? Je kunt nu in één keer kiezen voor een lege string waardoor n=0 en m=0 en dat voldoet niet aan de formele beschrijving.
Je moet dus productieregels maken waarbij je minimaal één b hebt. Dan zou je het zo kunnen doen.
S → AB
A → aAb | λ
Nu nog een regel die één of meerdere regels produceert.
B → Bb | b
Dus onder elkaar:
S → AB
A → aAb | λ
B → Bb | b
9. JFlap
JFlap is tool wat ons helpt om een automaat te maken en uit te proberen. JFlap is hier te downloaden. JFlap heeft geen rechten nodig, alleen Java. Je kunt JFlap starten door dubbel te klikken op JFLAP8_beta.jar. Mocht Jflap het niet doen, dan even opnieuw Java installeren (oude versie eerst deïnstalleren).
Je kunt JFlap op diverse manieren grammatica's testen. We zullen een voorbeeld geven van onderdeel 1.8 waarin we een grammatica hebben gemaakt. Klik in JFlap op Grammar.
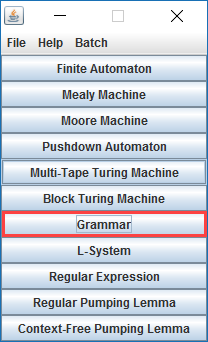
Je bent nu in staat om een grammatica in te voeren en te testen. De grammatica uit onderdeel 1.7 was:
S → AB
A → aAb | λ
B → Bb | b
Deze kun je invoeren door te dubbelklikken op de invoervakjes. De pipe (|) gebruik je niet maar je voert een apart veld in.
Onderin zie je tevens de grammatica verschijnen inclusief de hulpsymbolen.
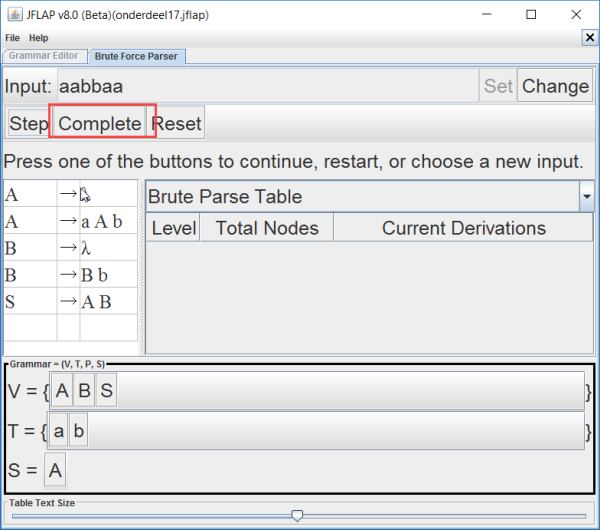
Nu kun je testen welke strings deze grammatica accepteert. Dit kun je testen door te klikken op Brute Force Parse.
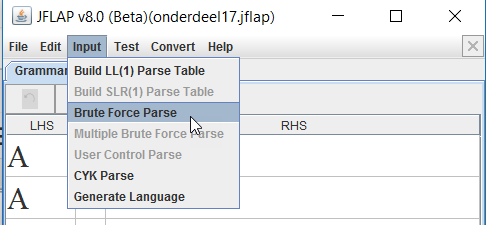
Vervolgens kun je testen welke strings de automaat accepteert door deze achter de input in te voeren en vervolgens te klikken op SET.
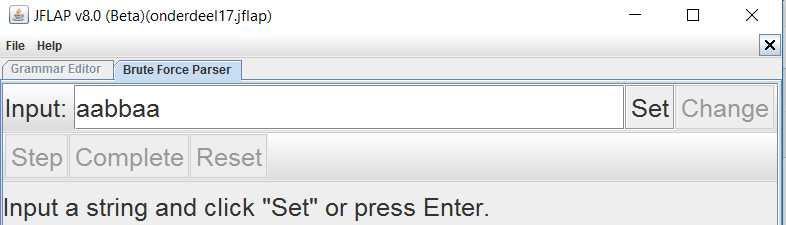
Als je daarna klikt op Complete kun je zien of een string wordt geaccepteerd. In bovenstaand geval is dat niet zo (Input recected!).
10. antwoorden deel 1
Opdracht 2.1
Nee, je hebt namelijk ook spaties en leestekens nodig.
Opdracht 3.1
L={λ,ab,ba,aabb,abba,abab,bbaa,baab,baba}
Opdracht 3.2
String nummer 1 en 2 kunnen wel. De derde string kan niet.
- ab aa baa ab aa
- aa aa baa aa
- baa aa ab aa aa b kan niet vanwege de losse b
Opdracht 3.3
L={λ,a,b,ab,ba,aa,bb,aab, aba,baa,bba, bab,abb,aabb,bbaa,abba, aabb, abab}
18 strings
Dat komt omdat er nu 2 x zoveel mogelijkheden zijn dus 2 x 9 = 18 + de lege string
Opdracht 4.1
|λ| = 0
Opdracht 4.2
L' = {a,b,ab,ba,aab…} dus zonder de λ
Opdracht 4.3
L={w∈{a,b} : |w| ≥ 0} of eigenlijk L=(w∈{a,b})
Dus hier kan ook de λ worden gemaakt
Opdracht 5.1
Bijvoorbeeld
De man rent
een vrouw wandelt
maar ook:
het hond rent
Het is immers niet de Nederlandse taal maar de gegeven taal.
Een zin zoals "het kind eet" kan niet. Eet is geen eindsymbool.
Opdracht 5.2
V staat voor hulpsymbool of variabele en bestaat in de gegeven grammatica uit het gezegde, het onderwerp, lidwoord, werkwoord en het zelfstanding naamwoord.
P staat voor Productiergels en zijn de regels waar een correcte zin aan moet voldoen.
T staat voor eindsymbool en dat zijn de symbolen die verder niet te ontleden zijn. Dit zijn:
- rent
- wandelt
- de
- het
- een
- man
- vrouw
- hond
Opdracht 6.1
w ⇒ uxv ⇒ uyv ⇒ uzv
Opdracht 7.1
Een afleiding is als volgt:
S=>AaAaAa=>..a...a..a
Op de plaats van de puntjes mag je nu kiezen voor een a, een b of een lege string vanwege A → aA | bA | λ
De verdere afleiding is dus
S=>AaAaAa=>babaλa=>babaa
of
S=>AaAaAa=>aaaaaa
of
S=>AaAaAa=>aaa
Een formele definitite is bijvoorbeeld L={axaxax: x element uit {a,b} }*
opdracht 7.2
Een afleiding geeft het volgende
S=>λ
of
S=>aA=>abS=>ab
of
S=>aA=>abS=>abaA=>ababS=>abab
Met andere woorden: er wordt één of meerdere de string ab geproduceerd. Formeel kunnen we dit als volgt opschrijven:
L={(ab)n : n > 0}
Het volgende antwoord is niet goed:
L={anbn : n > 0} omdat dit bij bijvoorbeeld n=2 aabb oplevert.
Opdracht 8.1
S = aSbb | λ
Opdracht 8.2
S → aSb | ab | λ
S → aAb | ab
A → aAb | λ
Bij de eerste productieregel kun je meteen vanuit S een lege string maken. Dat is bij de 2e set niet mogelijk. M.a.w. ze zijn niet equivalent.
opdracht 8.3
S → aSb | bSa | SS | a
S → aSb | bSa | a
Je kunt het beste meteen bij de volgende afleiding beginnen
S=>SS=>aSbaSb=>aabaab
Deze string kan niet worden gemaakt door de onderste productieregels.